About the data
The data for this analysis is a set of crossword clues and answers from New York Times crossword puzzles from 1996-2012, courtesy of Michael Donohoe:
https://github.com/donohoe/nyt-crossword
Calculating "crosswordiness"
Crosswordiness is calculated as a function of both how often a word appears in the crossword puzzle and how often it appears elsewhere. The "elsewhere" is the word's Google Books Ngram percentage from the same period, 1996-2012. For data quality reasons, only recognized dictionary words have their "crosswordiness" calculated (see Flaws below). Sorry, ARLO. The crosswordiness percentile of any answer word can be looked up from the Details page.
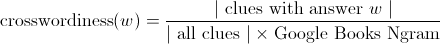
Calculating strength of clue-answer word pairs
To calculate how strongly a given word in a clue points to a particular answer, I use term frequency-inverse document frequency. This is a measure of not just how frequently a word appears in clues for a particular answer, but how frequently it appears in those clues relative to all clues. Chopping crossword clues into individual words has a significant margin of error (See Flaws below).
To see the three clue words that most strongly point to a given answer, check out the Details page. Examples: OLEO, APSE, EWER
Flaws
- Answers that aren't recognized English words (e.g. proper nouns, multi-word phrases) are excluded from the "crosswordiness" analysis, because it's especially hard to get reliable n-grams for them.
- The question of "what is a word?" is not a simple one, especially when it comes to breaking the clue text into constituent words. Crossword clues have their own ARGOT and use lots of abbreviations, so the results are far from perfect. Some non-words sneak in, and some legitimate words are left out.
- Some answers are used one way in the puzzle but counted differently by me out of context because they're homographs. For example, the crossword answer LENO generally refers to Jay, but it is also a word for a specific sort of yarn weave.
- 2006 data is missing from the original dataset.
- Some of the cells in the original dataset are garbled or empty.